
Data Science
-

Ein verantwortungsvoller Umgang mit digitalen Daten umfasst nicht nur deren Speicherung, sondern auch die sichere Löschung. Ob im privaten oder beruflichen Bereich: Datenschutz beginnt mit der Sensibilisierung für das Thema und endet mit der konsequenten Umsetzung sicherer Löschverfahren.
-

Seit April 2021 leite ich die Arbeitsgruppe Industrie 4.0 im KI Bundesverband e.V., dem größten deutschen Netzwerk an Unternehmen, Startups und Entwickler:innen im Bereich künstlicher Intelligenz. Unsere Arbeitsgruppe ist dabei immer auf der Suche nach Kontakten in die Industrie, um die Herausforderungen in diesem Bereich besser verstehen zu können.
-

Im beruflichen und privaten Umfeld nutze ich viele Produkte aus dem Google Workspace. Für den Digitaltag 2021 habe ich zum ersten Mal Google Apps Script verwendet, um die Funktionalitäten von Google Sheets zu erweitern für die Durchführung einer Open Data Rallye durchgeführt von Code for Bielefeld. Alle Infos dazu findet ihr auch in unserem Github…
-
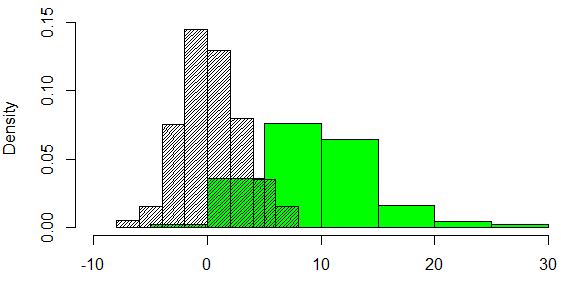
Im Beitrag zum Farmhack 2019 hatte ich bereits über die von mir bearbeitete Challenge berichtet. Wir waren insgesamt sieben Teammitglieder und hatten die Entwicklungsaufgaben aufgesplittet. Hier eine kurze Skizze meines Lösungsbeitrags mit R Code:
-
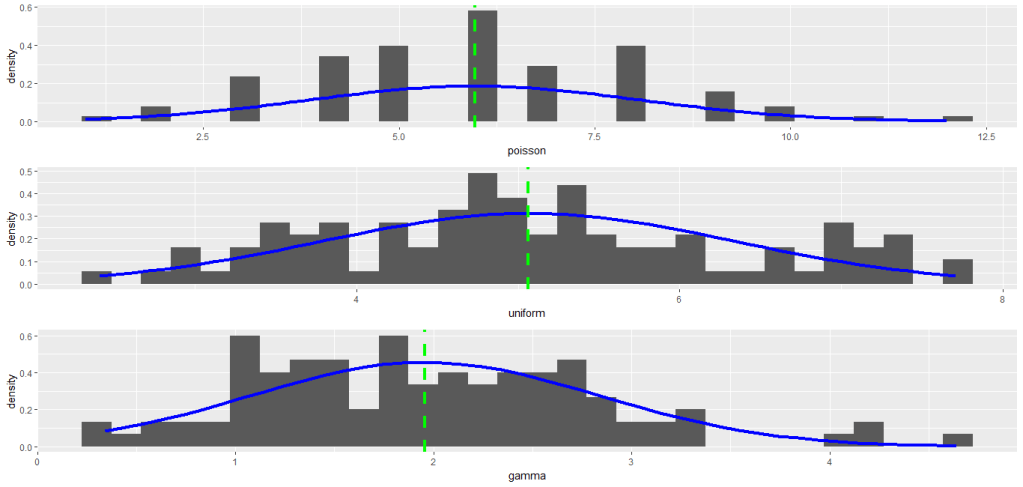
Zur Vorbereitung meiner Vorlesung Statistik der Datenanalyse im Masterstudium Digitale Technologien an der FH Bielefeld habe ich heute u.a. die Vermittlung des Zentralen Grenzwertsatzes (ZGW) vorbereitet und einige Grafiken dazu in R erstellt.
-
Die Inhalte der Warenkörbe lassen Rückschlüsse auf die eigenen Kunden zu. Gibt es Warenkorbinhalte, die häufig zusammengekauft werden? Kann ich Informationen über meine Kundengruppen ableiten? Eine Möglichkeit ist die Assoziationsanalysen. Aufgrund der Häufigkeiten von gemeinsam gekauften Produkten werden Regeln abgeleitet: Wenn X gekauft wird, dann wird auch Y gekauft. Das lässt allerdings die Heterogenität der…
-
Wir vom Data Science Bielefeld Team freuen uns, am 11.7.2019 um 19 Uhr in der Bürgerwache Bielefeld gleich zwei Referenten begrüßen zu dürfen. Zum einen kommt Matthias Ulrich, REWE Digital GmbH, zu uns mit einem Vortrag zum Thema „Distributional regression and model selection for demand forecasting in e-grocery“.
-
Machine Learning versucht, basierend auf Erfahrungen Wissen über Entscheidungen zu generieren mit dem Ziel selbständig Entscheidungen treffen zu können. Erfahrungen sind dabei i.d.R. Daten aus der Vergangenheit, sogenannte Trainingsdaten. Die gewählten Trainingsdaten beeinflussen stark die Qualität der Entscheidungen, die der ML Algorithmus nach dem Training selbständig trifft. Nur so gut, wie die vergangenen Entscheidungen waren,…
-
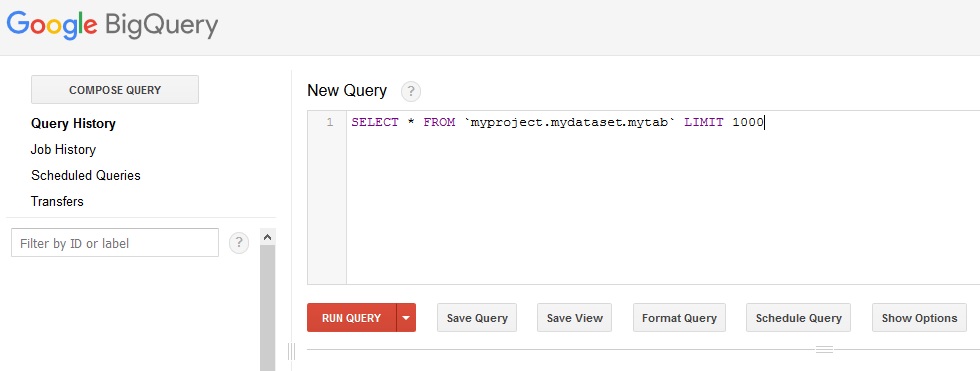
BigQuery ist ein leicht skalierbares Data Warehouse in der Google Cloud. Mit Standard SQL Abfragen kann auf Daten zugegriffen werden und mittels R-Paket bigrquery kann ich Daten aus BigQuery auch leicht in R verwenden. BigQuery, der Hidden Champion von Google 🙂
