
Im Beitrag zum Farmhack 2019 hatte ich bereits über die von mir bearbeitete Challenge berichtet. Wir waren insgesamt sieben Teammitglieder und hatten die Entwicklungsaufgaben aufgesplittet. Hier eine kurze Skizze meines Lösungsbeitrags mit R Code:
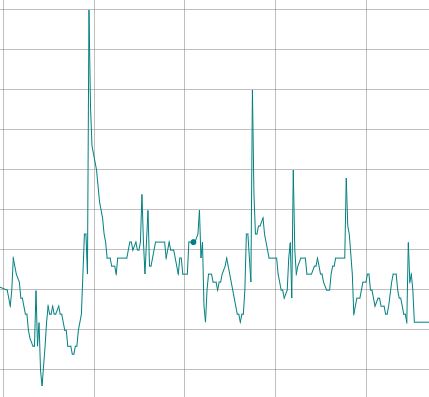
Teilherausforderung 1: Ein Parameter in den Daten wurde nicht kontinuierlich gesendet, daher waren Zeitfenster mit kontinuierlichem Signal zu finden.

Der Verlauf der Zeitreihe des Parameters in dem jeweiligen Zeitfenster war zu charakterisieren, damit diese Information im Algorithmus zur Zustandsdetektion verwendet werden kann
Teilherausforderung 2: Zählen der Peaks in der Zeitreihe + Definition lokaler Peak
Teilherausforderung 3: Messung der Abweichung des Verlaufs von einem Normalzustand
Für die Aufgabe 1 habe ich die Differenzen in den Zeitstempeln (in event_time) angeschaut. Sind die Differenzen größer als 3 Sekunden gewesen, ist es ein Endpunkt einer Zeitreihe, die gemäß unserer Definition mindestens alle 3 Sekunden einen Messwert haben sollte. Von dem Endpunkt ausgehend habe ich dann rückwärtsgehend den Startpunkt gesucht, d.h. den letzten Eintrag bevor ich wieder eine Differenz größer als 3 Sekunden finde. In den Vektoren start und end stehen jetzt die Indizes der Start und Endzeitpunkte bezogen auf event_time.
diff.time <- diff(data$event_time)
end <- which(diff.time > 3)
start <- rep(NA, length(end)))
j <- 1
for( i in end ){
k <- i - 1
while(diff.time[k] < 4){ ifelse( k != 1, k <- k-1, break)}
# Sonderbehandlung, wenn keine weiteren Beobachtungen mehr
# rückwärtsgehend vorliegen
ifelse(k!=1, k <- k+1 , k <- 1)
start[j] <- k
j <- j + 1
}
Nachdem der Zeitraum festgelegt wurde, habe ich für die Aufgabe 2 alle Peaks in den definierten Zeitreihen gezählt. Dafür habe ich Teile von stats.stackexchange.com genutzt und angepasst.
# m gibt an, wie viele Beobachtungen rechts und links kleiner sein muessen, damit lokaler Peak vorliegt
count_peaks <- function (x, m = 25){
shape <- diff(sign(diff(x)))
pks <- sapply(which(shape < 0), FUN = function(i){
z <- i - m + 1
z <- ifelse(z > 0, z, 1)
w <- i + m + 1
w <- ifelse(w < length(x), w, length(x))
if(all(x[c(z : i, (i + 2) : w)] <= x[i + 1])) return(i + 1) else return(numeric(0))
})
pks <- unlist(pks)
# in pks sind nun alle Peaks aufgefuehrt
# ich brauche nur die Anzahl der Peaks
return(length(pks))
}
Zum Vergleich der Zeitreihenverläufe, habe ich die erste Differenz der Zeitreihen verwendet, um das Problem unterschiedlicher Niveaus zu vernachlässigen und um nur Informationen zur Bewegung der Zeitreihe zu haben. Eine bestimmter Zeitraum aus der Zeitreihe der Differenzen wurde als Normalverhalten definiert und die Abweichung zu dieser Zeitreihe mittels Earth-Mover-Distanz (EMD) berechnet. EMD berechnet Kosten, um Erde (Verteilung 1) in Loecher (Verteilung 2) zu füllen. Dafür werden Angaben zur Dichte der Verteilung (weight und location) benötigt. Diese berechne ich in R über die Histogramm Funktion.
library(emdist)
my.emd.fct <- function(x1, x2){
# breaks
br<-range(c(x1,x2))
br[1] <- floor(br[1])
br[2] <- ceiling(br[2])
hist.1<-hist(x1,breaks=br[1]:br[2], plot=FALSE)
hist.2<-hist(x2,breaks=br[1]:br[2], plot=FALSE)
m1<-matrix(c(hist.1$density, hist.1$mids),ncol=2)
m2<-matrix(c(hist.2$density, hist.2$mids),ncol=2)
return(emd(m1,m2))
}
Anwendung der Funtkion am Beispiel von zwei künstlich erzeugten Verteilungen:
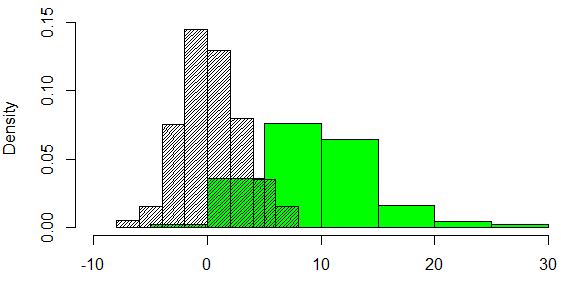
Beispiel 1 – großer Abstand zwischen zwei Normalverteilungen
set.seed(123)
test1<-rnorm(100,0,3)
test2<-rnorm(100,10,5)
hist(test1, xlim=c(-10,30), freq = FALSE)
hist(test2, add=TRUE, col="green", freq = FALSE)
hist(test1, add=TRUE, density=40, freq = FALSE)
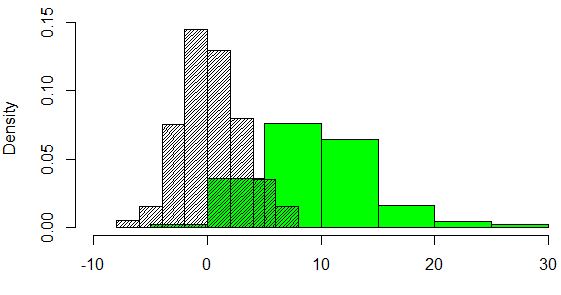
Berechnung des Abstands zwischen den Verteilungen:
my.emd.fct(test1, test2)
## [1] 9.15
Beispiel 2 – kleiner Abstand zwischen zwei gleichen Verteilungen
set.seed(123)
test1<-rnorm(100,0,1)
test2<-rnorm(100,0,1)
hist(test1, xlim=c(-4,5), freq = FALSE)
hist(test2, add=TRUE, col="green", freq = FALSE)
hist(test1, add=TRUE, density=40, freq = FALSE)

Berechnung des Abstands zwischen den beiden Verteilungen:
my.emd.fct(test1, test2)
## [1] 0.21
In Beispiel 1 ist der Abstand deutlich größer als in Beispiel 2.
