
Die Inhalte der Warenkörbe lassen Rückschlüsse auf die eigenen Kunden zu. Gibt es Warenkorbinhalte, die häufig zusammengekauft werden? Kann ich Informationen über meine Kundengruppen ableiten?
Eine Möglichkeit ist die Assoziationsanalysen. Aufgrund der Häufigkeiten von gemeinsam gekauften Produkten werden Regeln abgeleitet: Wenn X gekauft wird, dann wird auch Y gekauft. Das lässt allerdings die Heterogenität der Kundengruppe außer Acht. Es könnte sein, dass es eine Kundengruppe gibt, die zu Bratwürstchen immer Bier kauft, eine andere Kundengruppe hingegen zu Bratwürstchen kein Bier, dafür aber Salat-Zutaten im Warenkorb hat.
Eine andere Möglichkeit ist die Gruppierung der Warenkörbe zu verschiedenen Clustern. Clustering-Verfahren sind unsupervised, d.h. rein datengetrieben werden die Gruppen gebildet: innerhalb der Gruppe gibt es eine hohe Ähnlichkeit der Warenkorbinhalte, zwischen den Gruppen gibt es große Unterschiede.
Zum Clustern von Warenkörben verwende ich modell-basiertes Clustering. Dabei wird jedem Cluster unterstellt, dass es eine eigene Verteilungsfunktion mit Cluster-individuellen Parametern besitzt. Hier ist die Verteilung ein Mischmodell (finite mixture model) aus Binomialverteilungen (Produkt gekauft/nicht gekauft als Bernoulli Prozess). Zur Vereinfachung nehme ich an, dass sowohl die Warenkörbe voneinander unabhängig sind, als dass es auch keine Abhängigkeiten zwischen den Produktkaufentscheidungen gibt. Die Daten der Warenkörbe liegen in einer binären Matrix vor: jede Reihe steht für einen Warenkorb, jede Spalte gibt ein Produkt an, das entweder im Warenkorb vorhanden ist (= 1) oder nicht vorhanden ist (= 0).
Es wird ein simulierter Beispieldatensatz verwendet, der aus den Produkten Tomate, Gurke, Moehren, Milch, Kaese, Joghurt, Wurst, Schnitzel, Bratwurst, Zeitungen, Schreibwaren, Schokolade, Gummibaeren, Bonbons, Zahnpaste, Hautcreme, Deo, Windeln, Bier, Wein, Orangensaft in 200 Warenkörben besteht.
head(mybaskets)
## Tomate Gurke Moehren Milch Kaese Joghurt Wurst Schnitzel Bratwurst ## [1,] 1 1 1 1 0 1 0 0 0 ## [2,] 1 1 0 1 1 1 0 0 0 ## [3,] 1 1 1 1 0 1 0 0 0 ## [4,] 0 0 1 1 1 1 0 0 0 ## [5,] 0 1 1 1 1 1 0 0 0 ## [6,] 1 0 0 1 1 1 1 0 0 ## Zeitungen Schreibwaren Schokolade Gummibaeren Bonbons Zahnpaste ## [1,] 1 1 0 0 0 1 ## [2,] 1 1 0 0 0 1 ## [3,] 1 0 0 0 0 1 ## [4,] 1 1 0 0 0 1 ## [5,] 1 1 0 0 0 1 ## [6,] 1 1 0 0 0 1 ## Hautcreme Deo Windeln Bier Wein Orangensaft ## [1,] 1 1 0 0 0 0 ## [2,] 1 0 0 0 1 1 ## [3,] 0 1 0 0 0 0 ## [4,] 1 1 0 0 0 1 ## [5,] 1 1 0 0 0 0 ## [6,] 0 1 0 0 0 0
mybaskets.count <- apply(mybaskets, 2, sum)
mybaskets.count <- sort(mybaskets.count, decreasing = TRUE)
par(mar=c(8, 4, 3, 2) + 0.1)
plot(mybaskets.count, type="h", xaxt="n" ,ylim=c(30,180),xlab="",ylab="Freq",main="Häufigkeiten")
axis(1, at=1:21, labels=colnames(mybaskets), pos= 20, las=2)
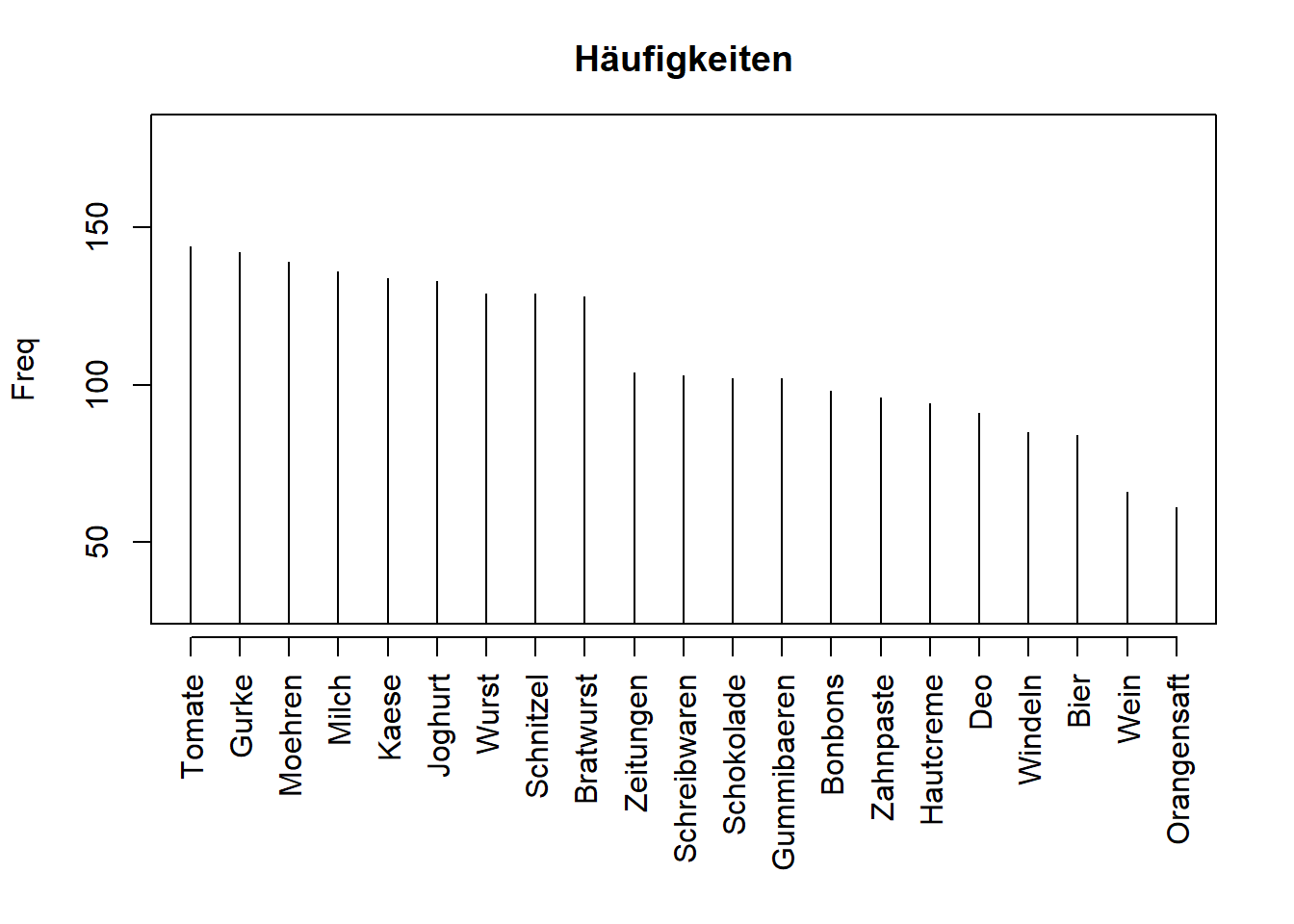
Hier ist der Datensatz klein und überschaubar. In der Realität sind deutlich mehr Warenkörbe zu verarbeiten. Zur Erhöhung der Rechengeschwindigkeit des Cluster-Verfahrens kann aus der binären Matrix eine Frequency-Matrix gebildet werden. Die Frequency-Matrix besitzt eine Spalte mit der Häufigkeit des Vorkommens der jeweiligen Zeile (= Warenkorb) in den Ursprungsdaten besitzt. Die Frequency-Matrix wird durch die Funktion count() aus dem R-Paket plyr erzeugt. Die Häufigkeiten werden als Gewichte im Cluster Verfahren verwendet.
library(plyr)
mybaskets.freq <- count(mybaskets)
head(mybaskets.freq[,16:22])
## x.Hautcreme x.Deo x.Windeln x.Bier x.Wein x.Orangensaft freq ## 1 1 0 0 1 0 0 1 ## 2 1 1 0 1 0 0 1 ## 3 0 0 1 1 1 0 1 ## 4 1 1 0 1 0 0 1 ## 5 1 1 0 1 0 0 1 ## 6 1 1 0 1 1 0 1
Das mixture model aus Binomial Verteilungen wird mit dem R-Paket flexmix geschätzt. Dort ist der EM Algorithmus implementiert, der 3 mal (nrep = 3) durchlaufen wird. In jedem Durchlauf wird jeder Warenkorb einem Cluster zufällig zugeordnet. Als model driver wird die Funktion FLXMCmvbinary() zum Clustern von binären Daten verwendet. Das Argument truncated wird gleich TRUE gesetzt, da wir nur Kunden beobachten können, die eine Kaufentscheidung getroffen haben. Kunden, die ohne etwas zu kaufen das Geschäft wieder verlassen haben, sind hier nicht berücksichtigt.
library(flexmix)
set.seed(123)
mybaskets_mix <- stepFlexmix(as.matrix(mybaskets.freq[,1:21]) ~ 1,
weights = ~mybaskets.freq$freq,
model = FLXMCmvbinary(truncated = TRUE),
control = list(minprior = 0.005), k = 1:7, nrep = 3)
Die Funktion stepFlexmix() clustert die Daten für k = 1 bis k= 7 Cluster. Das beste Modell, d.h. die beste Anzahl an Clustern kann dann mit Informationskriterien bestimmt werden, z.B. dem BIC.
mybaskets_best <- getModel(mybaskets_mix, "BIC")
mybaskets_best
## ## Call: ## stepFlexmix(as.matrix(mybaskets.freq[, 1:21]) ~ 1, weights = ~mybaskets.freq$freq, ## model = FLXMCmvbinary(truncated = TRUE), control = list(minprior = 0.005), ## k = 3, nrep = 3) ## ## Cluster sizes: ## 1 2 3 ## 30 107 63 ## ## convergence after 16 iterations
Die folgende Grafik zeigt die geschätzten Parameter für jedes Cluster. Dabei gibt der Parameter die Wahrscheinlichkeit an, dass das jeweilige Produkt sich im Warenkorb des Clusters befindet.
library(ggplot2)
library(plotly)
mybaskets_best.param <- data.frame("Produkte" = factor(colnames(mybaskets),
levels = colnames(mybaskets)),
"Parameter" = parameters(mybaskets_best),
row.names = NULL)
mybaskets_best.ggplot <- data.frame("Value" = c(mybaskets_best.param[,2],
mybaskets_best.param[,3],
mybaskets_best.param[,4]),
"Component" = c(rep(1, times=21),
rep(2, times=21),
rep(3, times=21)),
"Produkte" = rep(mybaskets_best.param$Produkte, times = 3))
g <- ggplot(mybaskets_best.ggplot,aes(y=Value,x=Produkte))+
geom_bar(stat='identity')+
coord_flip()+
facet_grid(.~Component)+
theme(axis.title.y = element_blank(),
axis.title.x = element_blank())
ggplotly(g, tooltip = c("Produkte"))
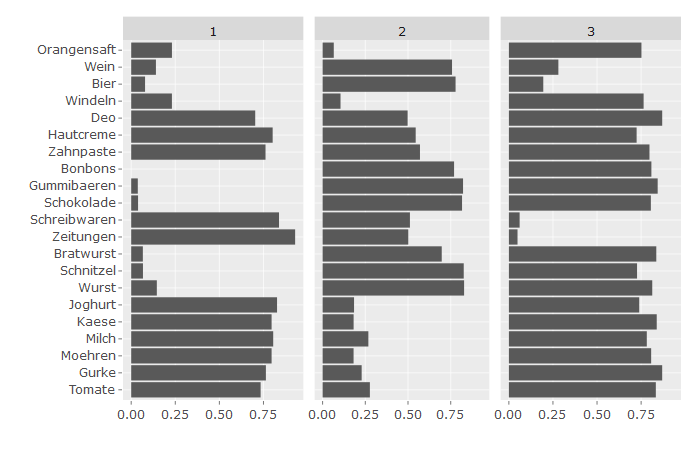
Das erste Cluster (15% der Warenkörbe) hat geringe Wahrscheinlichkeiten für Fleisch, Süßwaren und Alkohol, dafür aber die höchste Wahrscheinlichkeit für Schreibwaren und Zeitungen.
Cluster 2 (53,5% der Warenkörbe) hat eine geringe Wahrscheinlichkeit für Gemüse und Milchprodukte, aber eine hohe Wahrscheinlichkeit für Fleisch und Alkohol.
In Cluster 3 (31,5% der Warenkörbe) ist die Wahrscheinlichkeit für Windeln am höchsten ist, die Wahscheinlichkeit für Alkohol (Bier und Wein) sowie Zeitungen und Schreibwaren am niedrigsten.
Quelle: Grün, B. und Leisch, F. (2007), FlexMix: An R Package for Finite Mixture Modelling, R News, 7 (1), 8-13. https://ro.uow.edu.au/cgi/viewcontent.cgi?referer=https://www.google.com/&httpsredir=1&article=3410&context=commpapers (Abruf: 5.7.2019)
