
Machine Learning versucht, basierend auf Erfahrungen Wissen über Entscheidungen zu generieren mit dem Ziel selbständig Entscheidungen treffen zu können. Erfahrungen sind dabei i.d.R. Daten aus der Vergangenheit, sogenannte Trainingsdaten. Die gewählten Trainingsdaten beeinflussen stark die Qualität der Entscheidungen, die der ML Algorithmus nach dem Training selbständig trifft. Nur so gut, wie die vergangenen Entscheidungen waren, kann dann der Algorithmus auch für zukünftige Entscheidungen lernen. Eine Ausnahme ist dabei das Reinforcement Learning. Über ein Belohnungssystem lernt der Algorithmus selber, welche Entscheidung die Belohnung maximiert.
Anfang Januar 2019 hatten wir bei unserem Data Science Bielefeld Meetup (www.datascience-bielefeld.de) Marcus Cramer (Head of Analytics) und David Middelbeck (Head of Product) von Westphalia DataLab bei uns zu Gast, die etwas zu “Reinforcement Learning – Optimierung von Logistikprozessen” erzählt hatten. Marcus hatte mit dem windy gridworld eines der klassischen Reinforcement Learning Beispiele mitgebracht.
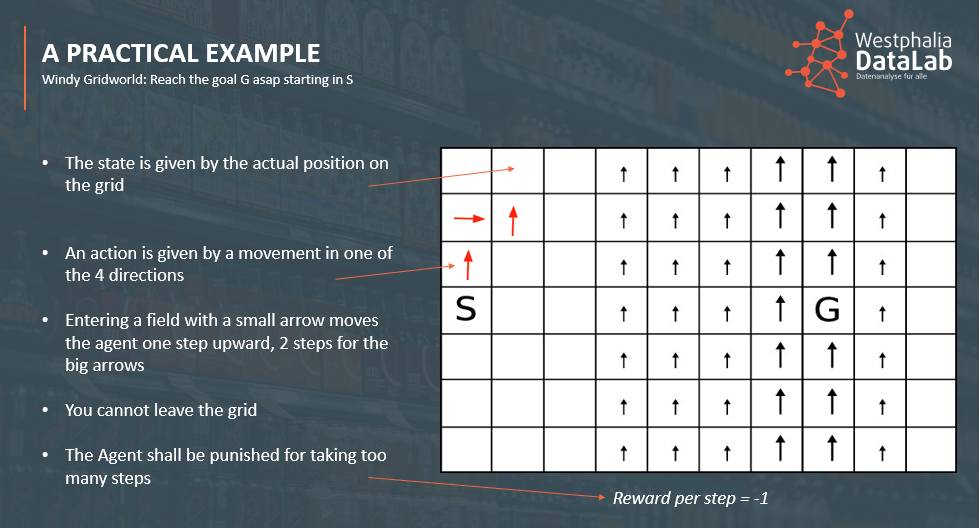
In dem Gitter-Spielplan ist vom Startpunkt S aus mit so wenig Zügen wie möglich das Feld G zu erreichen. Von jedem Feld aus kann hoch/runter/rechts/links gegangen werden. Ausnahme sind die Ränder, da der Spielplan nicht verlassen werden darf. In den Spalten mit den Pfeilen gibt es Seitenwinde, die den Spieler ein Feld (kleiner Pfeil) oder auch zwei Felder (großer Pfeil) nach oben tragen.
Marcus hatte es in Phython mit SARSA gelöst (https://github.com/MarcusCramer91/WindyGridworld/blob/master/src/WindyGW_Sarsa.py). Ich habe den Vortrag und das Beispiel zum Anstoß genommen, das R Paket ReinforcementLearning auszuprobieren.
Das R Paket ReinforcementLearning beinhaltet (im Moment) Q-learning und Experience Replay. Der Algorithmus lernt die optimale Policy dabei basierend auf gemachten Erfahrungen, so dass jede Beobachtung in den Trainingsdaten aus einem Tupel ((s_i), (a_i), (r_{i+1}), (s_{i+1})) besteht, mit
- (s_i) Ausgangszustand und (s_{i+1}) Folgezustand
- (a_i) gewählte Aktivität im Ausgangszustand, um Folgezustand zu erreichen
- (r_{i+1}) Belohnung für das Erreichen des Folgezustands.
Falls solche Trainingsdaten nicht vorliegen, besitzt das R Paket eine Funktion, um ein Sample an Daten zu generieren. Dafür muss das zu lösende Problem und sein dynamisches Umfeld, beeinflussende Faktoren, etc. in einer Funktion beschrieben werden. Das Ergebnis ist eine optimale Strategie, die für jeden möglichen Zustand die bestmögliche Aktivität angibt.
Als Vorarbeit muss zuerst das Paket geladen werden und das Spielfeld, sowie die Spalten mit Seitenwinden definiert werden.
library(ReinforcementLearning)
state.final <- "S_8_4"
grid.height. <- 7
grid.width. <- 10
sidewind.light. <- c(4:6,9)
sidewind.heavy. <- 7:8
Danach definiere ich die möglichen Aktivitäten für den Spieler, der sich auf dem Spielfeld nach oben, unten, rechts und links bewegen kann. Zusätzlich muss ich alle Felder S_1_1 bis S_10_7 in meinem Gitter als mögliche Zustände angeben.
actions <- c("up", "down", "left", "right")
states <- rep(NA, times = grid.height. * grid.width.)
k <- 1
while(k <= grid.height. * grid.width.){
# edge of the grid
if(k%%grid.width. == 0){states[k]<-paste("S", grid.width., floor(k/grid.width.), sep="_")}else{
states[k]<-paste("S", k%%grid.width., floor(k/grid.width.)+1, sep="_")}
k <- k+1
}
states
## [1] "S_1_1" "S_2_1" "S_3_1" "S_4_1" "S_5_1" "S_6_1" "S_7_1" ## [8] "S_8_1" "S_9_1" "S_10_1" "S_1_2" "S_2_2" "S_3_2" "S_4_2" ## [15] "S_5_2" "S_6_2" "S_7_2" "S_8_2" "S_9_2" "S_10_2" "S_1_3" ## [22] "S_2_3" "S_3_3" "S_4_3" "S_5_3" "S_6_3" "S_7_3" "S_8_3" ## [29] "S_9_3" "S_10_3" "S_1_4" "S_2_4" "S_3_4" "S_4_4" "S_5_4" ## [36] "S_6_4" "S_7_4" "S_8_4" "S_9_4" "S_10_4" "S_1_5" "S_2_5" ## [43] "S_3_5" "S_4_5" "S_5_5" "S_6_5" "S_7_5" "S_8_5" "S_9_5" ## [50] "S_10_5" "S_1_6" "S_2_6" "S_3_6" "S_4_6" "S_5_6" "S_6_6" ## [57] "S_7_6" "S_8_6" "S_9_6" "S_10_6" "S_1_7" "S_2_7" "S_3_7" ## [64] "S_4_7" "S_5_7" "S_6_7" "S_7_7" "S_8_7" "S_9_7" "S_10_7"
Die dynamische Umgebung des Spiels wird in der environment-function my.windy.gridworld formuliert. Innerhalb dieser Funktion gibt es eine state-action function, die als Eingangsparameter einen Zustand, d.h. ein Feld (State) zwischen S_1_1 und S_10_7, sowie eine Aktivität (Action), also eine mögliche Bewegung auf dem Spielfeld hat. Die Funktion gibt mir dann den neuen Zustand, d.h. das neue Feld zurück, sowie eine Belohnung (Reward) für die gewählte Aktivität.
function.1 <- function(grid.height, grid.width, sidewind.light, sidewind.heavy){
function(state, action){
#state: char2num
state2 <- strsplit(state, "_")
state2 <- list("width" = as.numeric(state2[[1]][2]), "height" = as.numeric(state2[[1]][3]))
next.state <- state2
#define actions
if(action == "up"){ next.state[["height"]] <- state2[["height"]] + 1}
if(action == "down"){ next.state[["height"]] <- state2[["height"]] - 1}
if(action == "left"){ next.state[["width"]] <- state2[["width"]] - 1}
if(action == "right"){ next.state[["width"]] <- state2[["width"]] + 1}
# #ensure gridworld cannot be left
if( !((next.state[["height"]] > 0 ) & (next.state[["height"]] <= grid.height ) &
(next.state[["width"]] > 0) & (next.state[["width"]] <= grid.width)) ){ next.state <- state2 }
#apply crosswinds
if(next.state[["width"]] %in% sidewind.light){
next.state[["height"]] <- next.state[["height"]] + 1 }
if(next.state[["width"]] %in% sidewind.heavy){
next.state[["height"]] <- next.state[["height"]] + 2 }
#outside grid
if(next.state[["height"]] > grid.height){next.state[["height"]] <- grid.height}
next.state <- paste("S", next.state[["width"]], next.state[["height"]], sep="_")
#reward
reward <- if( (next.state == state.final)){10}else{-1}
#Return
out <- list(NextState = next.state, Reward = reward)
return(out)
}}
my.windy.gridworld <- function.1(grid.height = grid.height.,
grid.width = grid.width.,
sidewind.light = sidewind.light.,
sidewind.heavy = sidewind.heavy.)
Die environment-function my.windy.gridworld kann nun genutzt werden für das samplen von Beobachtungen. Ich erzeuge 50000 zufällige state-transition Tupels ((s_i), (a_i), (r_{i+1}), (s_{i+1})).
# Sample N = 50000 random sequences from the environment
data <- sampleExperience(N = 50000, env = my.windy.gridworld, states = states, actions = actions)
head(data)
## State Action Reward NextState ## 1 S_5_5 right -1 S_6_6 ## 2 S_8_5 up -1 S_8_7 ## 3 S_5_1 up -1 S_5_3 ## 4 S_8_4 left -1 S_7_6 ## 5 S_7_7 left -1 S_6_7 ## 6 S_2_7 left -1 S_1_7
Diese Daten werden nun genutzt, um ein optimales Verhalten zu lernen. Das Lernverhalten kann durch Parameter im Vektor control beeinflusst werden. In diesem Beispiel behalte ich die Standard-Werte bei: Learning-rate (alpha = 0.1), discount factor (gamma = 0.5) und (epsilon (exploration greediness) = 0.1). Mit den erzeugten Daten starte ich das Reinforcement Learning.
# Define reinforcement learning parameters
control <- list(alpha = 0.1, gamma = 0.5, epsilon = 0.1)
# Perform reinforcement learning
model <- ReinforcementLearning(data, s = "State", a = "Action", r = "Reward",
s_new = "NextState", control = control)
Die Policy kann ich mir direkt anschauen policy(model), aber für eine bessere Übersichtlichkeit stelle ich die gefundene Strategie grafisch mithilfe einer eigenen Funktion, die das Spielfeld, sowie die Aktivitäten hoch/runter/links/rechts mit Pfeilen respektive (//) (hoch) und (\) (runter) skizziert.
print.result.fct <- function(model){
result.path <- policy(model)
result <- matrix(NA, ncol=grid.width., nrow = grid.height.)
for(i in 1:length(result.path)){
result.path.coord <- strsplit(names(result.path[i]),"_")
result[c(grid.height.:1)[as.numeric(result.path.coord[[1]][3])],
as.numeric(result.path.coord[[1]][2])] <- result.path[i]
}
result[result == "right"] <- "->"
result[result == "up"] <- "//"
result[result == "down"] <- "\\"
result[result == "left"] <- "<-"
print(result)
}
print.result.fct(model)
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [1,] "//" "<-" "\\" "->" "->" "->" "->" "->" "->" "\\" [2,] "\\" "\\" "<-" "->" "->" "->" "->" "->" "->" "\\" [3,] "//" "\\" "<-" "->" "->" "->" "->" "->" "->" "\\" [4,] "->" "\\" "->" "->" "->" "->" "->" "->" "->" "\\" [5,] "<-" "//" "->" "->" "->" "->" "->" "\\" "->" "\\" [6,] "//" "<-" "->" "->" "->" "->" "->" "\\" "<-" "\\" [7,] "//" "<-" "->" "->" "->" "->" "->" "//" "<-" "<-"
Das ist noch nicht optimal, daher generiere ich einen weiteren Trainingsdatensatz, der die erste gefundene Strategie als Input-Parameter mitbekommt. Die Aktivitäten werden mit dem epsilon – greedy Verfahren bestimmt: der Anteil epsilon der Aktivitäten wird zufällig gewählt, der Rest bestimmt sich aus der Strategie des ersten Modells.
# Updating an existing policy: generating new data
# Sample N = 100000 sequences from the environment using epsilon-greedy action selection
data_new <- sampleExperience(N = 100000, env = my.windy.gridworld, states = states, actions = actions, model = model, actionSelection = "epsilon-greedy", control = control)
Die neuen Trainingsdaten verwende ich zum Update des bestehenden Modells. Ich erhalte eine Strategie, die mich zum Zielfeld S_8_4 führt.
# Update the existing policy using new training data
model_new <- ReinforcementLearning(data_new, s = "State", a = "Action", r = "Reward", s_new = "NextState", control = control, model = model)
print.result.fct(model_new)
## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] ## [1,] "->" "->" "->" "->" "->" "->" "->" "->" "->" "\\" ## [2,] "->" "->" "->" "->" "->" "->" "->" "->" "->" "\\" ## [3,] "->" "->" "->" "->" "->" "->" "->" "->" "->" "\\" ## [4,] "->" "->" "->" "->" "->" "->" "->" "->" "->" "\\" ## [5,] "->" "->" "->" "->" "->" "->" "->" "\\" "->" "\\" ## [6,] "->" "->" "->" "->" "->" "->" "->" "\\" "<-" "\\" ## [7,] "->" "->" "->" "->" "->" "->" "->" "//" "\\" "<-"
